-
/Hans+de+Vries+Bulldozer.jpg)
Интересное развитие VLIW
"мультиклеточные" (С) процессорыТеги:
 Татарин
Татарин

Описание - тут:
http://www.multiclet.com/docs/verstka.pdf
http://www.multiclet.com/docs/verstka.pdf
...А неубитые медведи делили чьи-то шкуры с шумом.
Боюсь, мы поздно осознали, к чему всё это приведёт.


 инфо
инфо инструменты
инструменты Wyvern-2
Wyvern-2

Татарин> Описание - тут:
Татарин> http://www.multiclet.com/docs/verstka.pdf
Мне не понравилось. У меня была другая идея: VVLIW - Variable Very Long Instruction Word
Суть проста - в процессоре избыточное количество вычислительных устройств, из которых препроцессор формирует линейку командного слова в зависимости от последовательности команд. Как то так.
Татарин> http://www.multiclet.com/docs/verstka.pdf
Мне не понравилось. У меня была другая идея: VVLIW - Variable Very Long Instruction Word
Суть проста - в процессоре избыточное количество вычислительных устройств, из которых препроцессор формирует линейку командного слова в зависимости от последовательности команд. Как то так.
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης

 Серокой
Серокой

Wyvern-2> Как то так.
На соблюдении когерентности всё достигнутое в производительности помрёт.
Если я верно понял принцип - то есть разбиение препроцессором последовательных инструкций на много ядер.
На соблюдении когерентности всё достигнутое в производительности помрёт.
Если я верно понял принцип - то есть разбиение препроцессором последовательных инструкций на много ядер.
Больше не раскалятся ваши колосники. Мамонты пятилеток сбили свои клыки. ©

Wyvern-2> Суть проста - в процессоре избыточное количество вычислительных устройств, из которых препроцессор формирует линейку командного слова в зависимости от последовательности команд. Как то так.
?")
В твоём описании это чистый суперскаляр, как он есть (абсолютное большинство современных высокопроизводительных процессоров). Это если мы говорим о случае "много ALU/один конвеер". Там тоже поток команд кучкуется, затем наиболее выгодным образом переупорядочивается и раскидывается по исполнителям.
Или опиши отличия.
Идея ребят как я её понял: суть в наличии доступа каждого ALU к результатам каждого, доступа с нулевой латентностью.
Что позволяет гибче перераспределять выполнение, фактически уничтожить расходы на синхронизацию результатов, серьёзно расширить доступный "регистровый пул" (ну или как назвать совокупность регистров каждой клетки?) и сильно уменьшить необходимую толщину канала в память без вских кешей.
?
В твоём описании это чистый суперскаляр, как он есть (абсолютное большинство современных высокопроизводительных процессоров). Это если мы говорим о случае "много ALU/один конвеер". Там тоже поток команд кучкуется, затем наиболее выгодным образом переупорядочивается и раскидывается по исполнителям.
Или опиши отличия.
Идея ребят как я её понял: суть в наличии доступа каждого ALU к результатам каждого, доступа с нулевой латентностью.
Что позволяет гибче перераспределять выполнение, фактически уничтожить расходы на синхронизацию результатов, серьёзно расширить доступный "регистровый пул" (ну или как назвать совокупность регистров каждой клетки?) и сильно уменьшить необходимую толщину канала в память без вских кешей.
...А неубитые медведи делили чьи-то шкуры с шумом.
Боюсь, мы поздно осознали, к чему всё это приведёт.

Серокой> Если я верно понял принцип - то есть разбиение препроцессором последовательных инструкций на много ядер.
Я не все их бумажки ещё прочитал, но с наскока не дошло. Что такое триады именно? Ясно что это промежуточный код какой-то, но почему "триады" и триады чего? Как у них решается проблема тупого кодера/компилятора, когда программа лазит по всей памяти и без обращений к ней никакими фокусами не обойтись? И ещё не понял чем это всё лучше современной ФПГА с сотнями арифметических ядер и распределённой памятью, кроме того что ядра не дробные.
Я не все их бумажки ещё прочитал, но с наскока не дошло. Что такое триады именно? Ясно что это промежуточный код какой-то, но почему "триады" и триады чего? Как у них решается проблема тупого кодера/компилятора, когда программа лазит по всей памяти и без обращений к ней никакими фокусами не обойтись? И ещё не понял чем это всё лучше современной ФПГА с сотнями арифметических ядер и распределённой памятью, кроме того что ядра не дробные.
Wyvern-2>> Суть проста - в процессоре избыточное количество вычислительных устройств, из которых препроцессор формирует линейку командного слова в зависимости от последовательности команд. Как то так.
Татарин> ?
Татарин> В твоём описании это чистый суперскаляр, как он есть....
Татарин> Или опиши отличия.
Возьмем простейшую Трансмету: http://www.ixbt.com/cpu/crusoe/crusoe1.gif
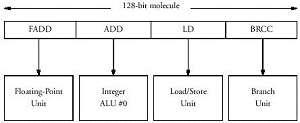
Четыре типа исполнительных устройства, длинна слова, соответственно 128 бит. НО! Они фиксированы, и если у нас идет подряд 9 операций условного перехода, то остальные устройства простаивают 9 циклов.
Теперь представим, что у нас есть пул исполнительных устройств: 4 ALU, 4 FPU, 4 блока переходов и 4 блока работы с памятью. Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
Т.е. или сразу 4 АLU или 4 блока работы с памятью, или 3 FPU и один блок перехода - любая комбинация, в рамках кода пока либо не кончатся исполнительные устройства, либо не будет повтора.
Как то так...
Татарин> ?
Татарин> В твоём описании это чистый суперскаляр, как он есть....
Татарин> Или опиши отличия.
Возьмем простейшую Трансмету: http://www.ixbt.com/cpu/crusoe/crusoe1.gif
Четыре типа исполнительных устройства, длинна слова, соответственно 128 бит. НО! Они фиксированы, и если у нас идет подряд 9 операций условного перехода, то остальные устройства простаивают 9 циклов.
Теперь представим, что у нас есть пул исполнительных устройств: 4 ALU, 4 FPU, 4 блока переходов и 4 блока работы с памятью. Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
Т.е. или сразу 4 АLU или 4 блока работы с памятью, или 3 FPU и один блок перехода - любая комбинация, в рамках кода пока либо не кончатся исполнительные устройства, либо не будет повтора.
Как то так...
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης

Wyvern-2> Теперь представим, что у нас есть пул исполнительных устройств: 4 ALU, 4 FPU, 4 блока переходов и 4 блока работы с памятью. Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
А разве не так же сейчас х86 проц работают? В описаниях постоянно встречаются слова типа конвейер, предварительное исполнение, макрооперации и т.д.?
Пс вот например типичное описание процессора годовой давности
===
Bobcat — это 15-стадийный 2-путный суперскаляр с внеочередным (OoO) исполнением команд и разнообразными оптимизациями вспомогательных блоков для максимального использования весьма скудных ресурсов. Среди улучшений — развитый предсказатель ветвлений и 2-уровневые буферы преобразования виртуального адреса в физический (TLB), чем ещё недавно могло похвастать лишь ядро K10 и ЦП Intel. AMD также отказалась от давно используемой схемы предварительной разметки границ команд — тут определение длины делается динамически, как у «больших» ЦП Intel. По утверждению AMD, в 89% случаев декодеры смогут поддерживать максимальный темп в 2 мопа/такт.
===
А разве не так же сейчас х86 проц работают? В описаниях постоянно встречаются слова типа конвейер, предварительное исполнение, макрооперации и т.д.?
Пс вот например типичное описание процессора годовой давности
===
Bobcat — это 15-стадийный 2-путный суперскаляр с внеочередным (OoO) исполнением команд и разнообразными оптимизациями вспомогательных блоков для максимального использования весьма скудных ресурсов. Среди улучшений — развитый предсказатель ветвлений и 2-уровневые буферы преобразования виртуального адреса в физический (TLB), чем ещё недавно могло похвастать лишь ядро K10 и ЦП Intel. AMD также отказалась от давно используемой схемы предварительной разметки границ команд — тут определение длины делается динамически, как у «больших» ЦП Intel. По утверждению AMD, в 89% случаев декодеры смогут поддерживать максимальный темп в 2 мопа/такт.
===



Это сообщение редактировалось 28.12.2011 в 09:38
Татарин>> В твоём описании это чистый суперскаляр, как он есть....
Татарин>> Или опиши отличия.
Wyvern-2> Возьмем простейшую Трансмету:
Не. Чем отличается твоё от Трансметы или Трансмета от обычного Атлона, П4 или core2, я понимаю.
А вот чем твоё - отличается от обычного Атлона, П4 или core2?
Wyvern-2> Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
То, что ты называешь "препроцессором" в обычных суперскалярах называется "декодером". Он "просматривает код", преобразует х86 команды во внутренние микрокоманды проца, при надобности переупорядочивает их для оптимальной загрузки блоков и т.п.
В чем отличия-то?
Подход Трансметы как раз позволял от этого уйти, избавить от сложного и дорогого декодера, повышающего латентность и ограничивающего производительность. Мысль была в том, чтобы убрать его функциональность на этап компиляции: функция есть, а транзисторов нет. И производительность такого "декодера" бесконечна - он же отсутствует. Всё по ТРИЗу, как идеальное устройство - то, которого нет, при условии что функция выполняется, причём по сравнению с аппаратным декодером времени исполнения - выполняется идеально.
А ты предлагаешь вернуться к нему. И зачем?
У этих людей с "клетками" (хорошо! пусть на первый взгляд, взгляд дилетанта!) мысль пошла дальше и значительно глубже. Все эти плюсы VLIW остались, но изящно побороты некоторые минусы.
Татарин>> Или опиши отличия.
Wyvern-2> Возьмем простейшую Трансмету:
Не. Чем отличается твоё от Трансметы или Трансмета от обычного Атлона, П4 или core2, я понимаю.
А вот чем твоё - отличается от обычного Атлона, П4 или core2?
Wyvern-2> Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
То, что ты называешь "препроцессором" в обычных суперскалярах называется "декодером". Он "просматривает код", преобразует х86 команды во внутренние микрокоманды проца, при надобности переупорядочивает их для оптимальной загрузки блоков и т.п.
В чем отличия-то?
Подход Трансметы как раз позволял от этого уйти, избавить от сложного и дорогого декодера, повышающего латентность и ограничивающего производительность. Мысль была в том, чтобы убрать его функциональность на этап компиляции: функция есть, а транзисторов нет. И производительность такого "декодера" бесконечна - он же отсутствует. Всё по ТРИЗу, как идеальное устройство - то, которого нет, при условии что функция выполняется, причём по сравнению с аппаратным декодером времени исполнения - выполняется идеально.
А ты предлагаешь вернуться к нему. И зачем?
У этих людей с "клетками" (хорошо! пусть на первый взгляд, взгляд дилетанта!) мысль пошла дальше и значительно глубже. Все эти плюсы VLIW остались, но изящно побороты некоторые минусы.
...А неубитые медведи делили чьи-то шкуры с шумом.
Боюсь, мы поздно осознали, к чему всё это приведёт.
Это сообщение редактировалось 28.12.2011 в 10:45

Wyvern-2> Теперь представим, что у нас есть пул исполнительных устройств: 4 ALU, 4 FPU, 4 блока переходов и 4 блока работы с памятью. Препроцессор - или аппаратный, или программный (!) - просматривает код на некоторую глубину и формирует командное слово из тех блоков, которые нужны
Если оставить один блок переходов (а зачем 4?) и чуток урезать блоки то получается практически ... AMD Athlon
3 ALU + 2 FPU + 2 LSU, но максимум 3 команды за такт.
PS: Статейку не прочитал ещё.
Если оставить один блок переходов (а зачем 4?) и чуток урезать блоки то получается практически ... AMD Athlon
3 ALU + 2 FPU + 2 LSU, но максимум 3 команды за такт.
PS: Статейку не прочитал ещё.
... так пускай наступает на нас холодным рассветом новый день ...
au> Что такое триады именно? Ясно что это промежуточный код какой-то, но почему "триады" и триады чего?
Это не чисто их изобретение. Это так (почти?) любой компилятор работает, синтаксически разбивая код на тетрады или триады. Что-то вроде записи в калькулятор МК-54.
Это не чисто их изобретение. Это так (почти?) любой компилятор работает, синтаксически разбивая код на тетрады или триады. Что-то вроде записи в калькулятор МК-54.
Больше не раскалятся ваши колосники. Мамонты пятилеток сбили свои клыки. ©

Серокой> Это не чисто их изобретение. Это так (почти?) любой компилятор работает, синтаксически разбивая код на тетрады или триады.
Расшифруй. А то сколько я с компиляторами возился (в т.ч. и сам писал), но про что ты говоришь — не понимаю
Серокой> Что-то вроде записи в калькулятор МК-54.
А почему МК-54, это же экзотика?
Расшифруй. А то сколько я с компиляторами возился (в т.ч. и сам писал), но про что ты говоришь — не понимаю
Серокой> Что-то вроде записи в калькулятор МК-54.
А почему МК-54, это же экзотика?

Balancer> Расшифруй. А то сколько я с компиляторами возился (в т.ч. и сам писал), но про что ты говоришь — не понимаю
А это пре-компилятор, как я понимаю.
Вот нашёл поиском лекцию: http://www.ict.edu.ru/ft/005128//ch9.pdf
В самом конце PDF-а.
Balancer> А почему МК-54, это же экзотика?
Да любой, просто там типа обратной польской записи.
А это пре-компилятор, как я понимаю.
Вот нашёл поиском лекцию: http://www.ict.edu.ru/ft/005128//ch9.pdf
В самом конце PDF-а.
Balancer> А почему МК-54, это же экзотика?
Да любой, просто там типа обратной польской записи.
Больше не раскалятся ваши колосники. Мамонты пятилеток сбили свои клыки. ©
Серокой> В самом конце PDF-а.
Что-то крайне узкоспецифическое и сугубо теоретическое
Balancer>> А почему МК-54, это же экзотика?
Серокой> Да любой, просто там типа обратной польской записи.
Просто МК-54 — это был весьма малораспространённый вариант Б3-34 в корпусе от МК-61. Т.е. Б3-34, МК-61, МК-52 — удивления бы в этом контексте не вызвали, а вот МК-54 — это экзотика
...
Но там тоже не было этих "тетрад и триад". Система команд — обычный байткод, интерпретируемый процессором аппаратно. Байткод раскладывался на микрокоманды, которые по сути, кажется, аналог именно VLIW. Непосредственное управление примитивными операциями с регистрами.
Что-то крайне узкоспецифическое и сугубо теоретическое
Balancer>> А почему МК-54, это же экзотика?
Серокой> Да любой, просто там типа обратной польской записи.
Просто МК-54 — это был весьма малораспространённый вариант Б3-34 в корпусе от МК-61. Т.е. Б3-34, МК-61, МК-52 — удивления бы в этом контексте не вызвали, а вот МК-54 — это экзотика
...
Но там тоже не было этих "тетрад и триад". Система команд — обычный байткод, интерпретируемый процессором аппаратно. Байткод раскладывался на микрокоманды, которые по сути, кажется, аналог именно VLIW. Непосредственное управление примитивными операциями с регистрами.
Запутались  разбираемся: Классификация параллельных вычислительных систем — Википедия
разбираемся: Классификация параллельных вычислительных систем — Википедия
Суперскаляр:
VLIW:
При этом:
В моем случае ПЕРЕМЕННЫМ является СОСТАВ ВЫЧ.УСТРОЙСТВ В СЛОВЕ Переменным и зависящим от состава потока команд
разбираемся: Классификация параллельных вычислительных систем — ВикипедияСуперскаляр:
Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств.
Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд (англ. OoO, Out of Order execution), прогнозирование переходов (англ. Branch prediction), кэши целевых адресов переходов и условное (по предположению) выполнение команд.
VLIW:
В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором.
При этом:
Использование VLIW приводит в большинстве случаев к быстрому заполнению небольшого объема внутрикристальной памяти командами NOP (no operation), которые предназначены для тех устройств, которые не будут задействованы в текущем цикле.
В моем случае ПЕРЕМЕННЫМ является СОСТАВ ВЫЧ.УСТРОЙСТВ В СЛОВЕ
Переменным и зависящим от состава потока команд
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης
Wyvern-2> В моем случае ПЕРЕМЕННЫМ является СОСТАВ ВЫЧ.УСТРОЙСТВ В СЛОВЕ Переменным и зависящим от состава потока команд
А, так ты хочешь именно VLIW, а не суперскаляр? И такое было — Itanium.
Переменным и зависящим от состава потока командА, так ты хочешь именно VLIW, а не суперскаляр? И такое было — Itanium.
... так пускай наступает на нас холодным рассветом новый день ...
Wyvern-2>> В моем случае ПЕРЕМЕННЫМ является СОСТАВ ВЫЧ.УСТРОЙСТВ В СЛОВЕ Переменным и зависящим от состава потока команд
AXT> А, так ты хочешь именно VLIW, а не суперскаляр? И такое было — Itanium.
Не-а Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус
Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Переменным и зависящим от состава потока командAXT> А, так ты хочешь именно VLIW, а не суперскаляр? И такое было — Itanium.
Не-а
Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης
 Mishka
Mishka

Balancer> Что-то крайне узкоспецифическое и сугубо теоретическое
Не, это нормальная запись в дереве рабора и вычислений. Или 2-х операндная запись (триады — на уровне ассемблера — код операции, первый операнд, второй операнд, результат операции либо в первом, либо во втором — вариант с присвоением), или 3-х операндные (тетрады — код операции, первый операнд, второй операнд, результат). В их случае удобно, т.к. они говорят о прямом доступе с результату операции ячейки из другой ячейки (вопрос синхронизации окончания выполнения операции).
А так, вроде очень похоже на МДА архитектуру Калякина из далёких 80-х прошлого века.
Не, это нормальная запись в дереве рабора и вычислений. Или 2-х операндная запись (триады — на уровне ассемблера — код операции, первый операнд, второй операнд, результат операции либо в первом, либо во втором — вариант с присвоением), или 3-х операндные (тетрады — код операции, первый операнд, второй операнд, результат). В их случае удобно, т.к. они говорят о прямом доступе с результату операции ячейки из другой ячейки (вопрос синхронизации окончания выполнения операции).
А так, вроде очень похоже на МДА архитектуру Калякина из далёких 80-х прошлого века.

Wyvern-2> Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Оно там фиксированное только потому, что может адресоваться любое из имеющихся. Не хочешь адресовать (использовать) — не упоминай в слове.
Оно там фиксированное только потому, что может адресоваться любое из имеющихся. Не хочешь адресовать (использовать) — не упоминай в слове.
Wyvern-2> Не-а Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус
Wyvern-2> Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Не надо путать Эльбрус с Итаниумом, это принципиально разные архитектуры, что бы там Бабаян не нёс.
У Итаника — как раз переменное количество устройств в слове. Вплоть до трёх команд перехода. Всего 10 вариантов (да, они не стали делать совсем свободную кодировку), плюс несколько возможных позиций стоп-флага.
Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус Wyvern-2> Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Не надо путать Эльбрус с Итаниумом, это принципиально разные архитектуры, что бы там Бабаян не нёс.
У Итаника — как раз переменное количество устройств в слове. Вплоть до трёх команд перехода. Всего 10 вариантов (да, они не стали делать совсем свободную кодировку), плюс несколько возможных позиций стоп-флага.
... так пускай наступает на нас холодным рассветом новый день ...
Wyvern-2>> Там опять таки фиксированное число исполнительных устройств в слове А у меня - избыточное, для возможности создания переменного числа устройств в слове.
Mishka> Оно там фиксированное только потому, что может адресоваться любое из имеющихся. Не хочешь адресовать (использовать) — не упоминай в слове.
Угу. Но это минимализм - а у меня максимализм Предположим, "длинное слово" у нас в 8 операндов, исполняемых 8 устройствами - пусть 2 их них с плавающей запятой. А в программе одновременно 8 операций с FP.
VLIW: выполнит их по 2, остальные шесть "клеток" слова будет заполнять NOP
EPIC Итаниум: просмотрит дальше, и если ПОСЛЕ этих 8 операций найдет не FP-операции, вставит их в слово
Мой VVLIW: сформирует "временный процессор" из 8 FPU и выполнит все за один проход")
Mishka> Оно там фиксированное только потому, что может адресоваться любое из имеющихся. Не хочешь адресовать (использовать) — не упоминай в слове.
Угу. Но это минимализм - а у меня максимализм
Предположим, "длинное слово" у нас в 8 операндов, исполняемых 8 устройствами - пусть 2 их них с плавающей запятой. А в программе одновременно 8 операций с FP.VLIW: выполнит их по 2, остальные шесть "клеток" слова будет заполнять NOP
EPIC Итаниум: просмотрит дальше, и если ПОСЛЕ этих 8 операций найдет не FP-операции, вставит их в слово
Мой VVLIW: сформирует "временный процессор" из 8 FPU и выполнит все за один проход
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης
Это сообщение редактировалось 28.12.2011 в 16:49
Wyvern-2>> Не-а Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус
AXT> Не надо путать Эльбрус с Итаниумом, это принципиально разные архитектуры, что бы там Бабаян не нёс.
Не путаю - я их как рах сравнивал
AXT> ....Всего 10 вариантов (да, они не стали делать совсем свободную кодировку)...
В этом и суть! УЖЕ не имеет смысла экономить на количенстве транзисторов в устройствах - один хрен 90% транзисторов это кэш-память и регистры Избыточное количество устройств практически не увеличит размер кристалла.
Эта идея пришла ко мне как раз когда читал про Itanium и пресловутый Эльбрус AXT> Не надо путать Эльбрус с Итаниумом, это принципиально разные архитектуры, что бы там Бабаян не нёс.
Не путаю - я их как рах сравнивал
AXT> ....Всего 10 вариантов (да, они не стали делать совсем свободную кодировку)...
В этом и суть! УЖЕ не имеет смысла экономить на количенстве транзисторов в устройствах - один хрен 90% транзисторов это кэш-память и регистры
Избыточное количество устройств практически не увеличит размер кристалла.
Жизнь коротка, путь искусства долог, удобный случай мимолетен, опыт обманчив.... Ἱπποκράτης
Mishka> Или 2-х операндная запись (триады — на уровне ассемблера — код операции, первый операнд, второй операнд, результат операции либо в первом, либо во втором — вариант с присвоением), или 3-х операндные
Понятно. Тогда, хоть и распространённое, но всё равно специфичное. Регистровыми ассемблерами мир машинных кодов не ограничивается
Понятно. Тогда, хоть и распространённое, но всё равно специфичное. Регистровыми ассемблерами мир машинных кодов не ограничивается
Wyvern-2> В этом и суть! УЖЕ не имеет смысла экономить на количенстве транзисторов в устройствах - один хрен 90% транзисторов это кэш-память и регистры
Регистров мало, память [относительно] статична и конструктивно примитивна.
Посмотри на топологию современных процессоров — память там меньшую долю площади кристалла:

Регистров мало, память [относительно] статична и конструктивно примитивна.
Посмотри на топологию современных процессоров — память там меньшую долю площади кристалла:

Balancer> Посмотри на топологию современных процессоров — память там меньшую долю площади кристалла:
А ты глянь внимательно на ядро:
L2 буфер, регистровый файл, кэш инструкций, кэш данныйх 1 уровня... )
А ты глянь внимательно на ядро:
L2 буфер, регистровый файл, кэш инструкций, кэш данныйх 1 уровня... )
Больше не раскалятся ваши колосники. Мамонты пятилеток сбили свои клыки. ©
Copyright © Balancer 1997..2018
Создано 27.12.2011
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 27.12.2011
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.

{kind=link}